Machine Learning
Vision & Sensors
V&S
H2 Deck By Bold Name
h2 xxxxxx
H1 xxxxxx
h2 xxxxx

We’ll look at its practical implementation for machine vision inspection in industrial automation use cases. By David L. Dechow
Traditional Machine Learning for Practical Machine Vision: It’s Been There All Along
Powerful and practical machine learning tools for machine vision applications are already available to everyone, even if you’re not a data scientist. It might come as a bit of a surprise, but machine learning has been a vital part of machine vision for a long time and the function of these tools includes but is far broader than just deep learning. If you work with industrial machine vision you may already be implementing machine learning without knowing it. In this discussion we’ll define machine learning and how it works within machine vision with a focus on where machine learning can best be used to enhance inspection reliability and capability.
Machine learning is a technology that can provide value in many ways to improve production quality and efficiency in manufacturing and industrial automation. ML and “big data” play a key role in achieving the productivity and flexibility envisioned in initiatives like smart factories, smart manufacturing, and Industry 4.0. Our discussion though, will broadly present machine learning specifically as related to its practical implementation for machine vision inspection in industrial automation use cases.
What is machine learning and how is it used for machine vision?
Putting things in perspective, machine learning (ML) is a part of the overarching foundational concept of computer science which encompasses technical disciplines like data science and artificial intelligence (AI). These two are closely related and AI often is described as falling under the umbrella of data science. Machine learning fits well with both AI and data science in general but overall, ML is considered a branch of AI.
The familiar AI technique called “deep learning” is a subset of machine learning and is a widely discussed ML technique. Here however, we will focus on “traditional” machine learning, that is: ML algorithms that learn and execute without deep learning’s advanced multi-layer neural networks.
Traditional machine learning employs algorithms that apply statistical methods to create models that can analyze data and make predictions and classifications based on learning and without the need to explicitly program all characteristics of the information. Data scientists research, develop, improve and tune these algorithms. Machine vision engineers choose, train, and implement ML tools for specific applications. Of the many machine learning tools, deep learning may be the most familiar and perhaps most used. However, traditional ML algorithms still are well suited for many machine vision tasks and applications and in some cases can perform better or be more efficient than deep learning. As a starting point it will be useful to understand a general overview of machine learning.
Data science classifies machine learning algorithms under broad general types based on how they are trained with and/or work with data. The categories are:
- “Supervised Learning”: learns using known (labelled) data.
- “Unsupervised Learning”: finds patterns and groups unlabeled data.
- “Reinforcement Learning”: determines outcomes as it learns from changing inputs.
Another type called “Semi-supervised Learning” sometimes is included. And, some algorithms, like deep learning and some regressions, can be included in more than one category.
Algorithms in all categories are important but machine learning tools that support machine vision and image analysis primarily use supervised learning so our focus will be on this type of ML.
As the name suggests, supervised learning algorithms use “labeled” training data to learn how to map input data to output data by comparing the algorithm’s predictions with the training data. The algorithm then uses the learned mappings and parameters, the “model”, to make accurate predictions on new data and can adjust itself over time.
Supervised learning algorithms most commonly execute one of two main types of tasks: classification or regression. Classification is used to predict discrete correct label(s) for input data (as in object identification or defect detection based on trained images). Regression is used when the output information about the data is variable (for example, predicting the number of hours before expected failure of a mechanical component based on input data from the machine).
The many algorithms used in machine learning continue to evolve and grow. An itemization of all these tools, programming techniques, and how they work is a data science topic far beyond the scope of this discussion. For reference, here are some that might be found in practical machine vision applications. Note that some very common ML data analysis tools are not necessarily optimal for image or feature classification and are not included here but might nonetheless sometimes be implemented for images if appropriate.
Linear, logistic, and polynomial regressions – These tools fit linear or polynomial functions to a dataset for classification. Logistic regression can subsequently apply a simple neural network to refine a classification. Less common but possibly used in image classification.
Support Vector Machines (SVM) – Handles classification of data that are not separated linearly by adding dimensionality to the data based on the training dataset to create separation. Indicated for feature and image classification and OCR.
Decision trees – A simple method that classifies using rules gained from the training data and arranged as a tree structure with multiple binary decision nodes. Useful for simpler classification tasks.
k-NN – K-Nearest Neighbors is a fundamentally simple classifier that collects and stores all features and classes from the training set, then classifies new data based on the number of nearest neighbors in the training data using various techniques. Considered as supervised learning in segmentation, it also can be used with unsupervised learning as a technique called clustering. k-NN is fast and very effective for general feature classification and OCR.
Gaussian Mixture Models – “GMM”, also called a “Bayes Classifier” is a method that can use supervised or unsupervised learning and is a clustering technique as mentioned for k-NN. It is effective but can be limited in the number of features available. It is used for segmentation in some cases but can be useful in texture and anomaly detection.
Multilayer Perceptrons – MLPs are a form of a simple artificial neural network (ANN) related to but not deep learning (convolutional neural networks, CNNs) which is more complex. MLP usually have only 1 to 3 “hidden” layers. MLP algorithms work well with data that is difficult to classify linearly and are leaner and easier to use than deep learning but are not as efficient and powerful.
Are you already using traditional machine learning without knowing it? Perhaps, given some latitude in the definition. One could successfully argue for example, that pattern matching (“searching”), one of the most well-known machine vision tools, could be called “machine learning” because it is trained and learns from input data to classify features in the image. Other simple regressions and convolutions which could easily be related to ML underly many other machine vision algorithms.
Traditional machine learning vs. deep learning
Why not always just employ familiar and widely promoted deep learning for machine vision applications? The bottom line is that many machine vision tasks already are tightly constrained and well defined such that identification of key features does not require the complexity and power of deep learning algorithms.
The simpler traditional machine learning algorithms for automated imaging require less training data and demand much less processing power than deep learning. ML tools can be trained in seconds or minutes. The output results from ML algorithms generally can be characterized and analyzed and debugged where results from deep learning are difficult to impossible to define. Several commercially available machine vision software libraries as well as open source libraries like OpenCV and Scikit.Learn offer a wealth of ML tools readily available for implementation, often without subscriptions or cloud computing common to deep learning. However, ML requires greater human intervention in training and re-training, and input data must be extracted and structured as needed by the algorithm, often beyond just image content.
Deep learning excels in applications that are highly complex, non-linear, and subjective. As such computing and processing requirements are higher. Training requires many images but less engineering in most cases than simple ML. Continuous learning and retraining can be implemented but this process can require some human intervention and time. In some cases, training and even inference for deep learning models may be executed using cloud computing.
In short, traditional machine learning is a good choice when the classification or segmentation is clear and constrained and the features have some but generally limited variability, all common in many machine vision applications. Deep learning is always the choice when the detection or segmentation task is highly complex and subjective.
The ML workflow
The general workflow for implementing machine learning is perhaps a familiar one that can apply to many machine vision tasks:
- Collect images representing the features to be detected, reserving some for training and some for testing.
- Select an appropriate algorithm to test with the understanding that perhaps more than one algorithm should be evaluated.
- Train the model using prepared input data from the features as appropriate for the algorithm
- Evaluate, retrain as needed, and deploy.
One part of the process that might be less familiar is revealed in step 3 above: “using prepared data”. Unlike most machine vision tools, and even in contrast to most deep learning, some ML algorithms work not directly on image data but rather on pure data sometimes referred to as “feature vectors”. The features used relate to the objects that must be classified or segmented. For these algorithms, data must be carefully selected such that the algorithm can be the most successful in the subsequent designation of classes. The useful feature data might be geometric, texture, or color/grayscale information. The same data used for training is the input data used by the algorithm for feature classification.
One might ask, “Why not just program rules to check each part for specific information that uniquely identifies that object?”. This might be a good approach in some cases, but there can be significant value to using machine learning. Often, many features must be used to identify a unique class out of several possibilities, and these may have large variations that overlap from class to class. There may be many data points that have to be considered to fully define differences in the classes. It can be difficult to create a rules-based algorithm that is reliable for all input data. Furthermore, adding a new class could require significant adjustment of the existing rules. Machine learning overcomes these situations in that the algorithms once trained automatically perform the task of selecting the correct class from complex input data and can be retrained if additional objects are introduced. Of course, there are limitations depending on the tool selected.
To be clear, some ML algorithms are trained directly with image data. For this training only segmented and/or labeled features and images are required.
Implementing machine learning for machine vision
In conclusion, let’s look at a few examples of actual implementation of traditional machine learning algorithms in machine vision applications. (Images and test algorithms copyright MVTec.)
xxxxxxxx
xxxxxxx

In this example (Image 1), a GMM model is created to show a simple classification of fruit. Features selected to define the differences between the classes are object circularity and object area. Note that other features (like color) could be added to improve reliability. As mentioned, the value of the tool is that the classification is performed and tuned with little intervention.
xxxxxxxx
xxxxxxx
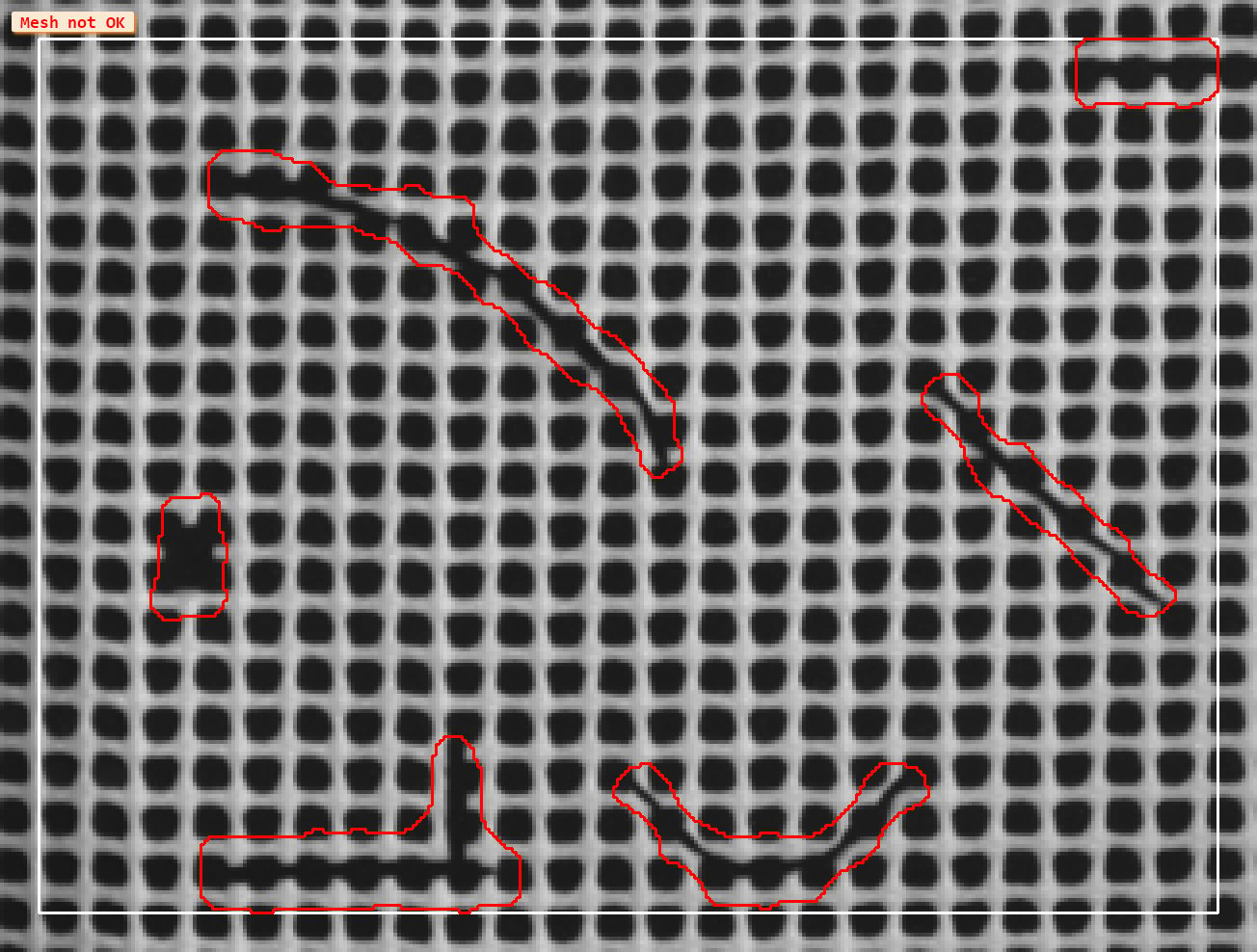
An SVM classifier can be statistically trained with feature vectors represented by images for detection of random defects. In this application (Image 2) the normal mesh varies somewhat but consistent texture data can be extracted from good images by applying specific convolutions. Anomalies that vary from the trained texture are then classified by the SVM as defects. As noted earlier, processing times with this type of statistical analysis are very short, often in just a few milliseconds.
xxxxxxxx
xxxxxxx

Classification of simple objects is shown in Image 3. With machine learning using a KNN classifier, the analysis of multiple data points related to the geometric structure of the parts is simple to learn and implement without exhaustive rule-based programming. For this example, execution is more efficient than either pattern matching or deep learning.
